xVASynth is an AI tool for generating high-quality speech, which is available on Steam/Nexus for free.
I plan on training some voice models from the Shenmue series for xVASynth. It may be useful for anyone who wants to add custom voiced lines to the game(provided you can re-import the audio that is), or you could simply use it just to play around with.
A basic rundown on how to use the software.
Installation: Copy and extract the voice model zip into the root directory of xVASynth.
Update: Ren was a failure. Will have to retrain at some point.
Bug: models marked with a ' * ' have quality degradation issues when generating sentences in succession(might just be my system). As a temporary fix: generate audio for desired model, type in new sentence, change to another model and generate, then switch back.
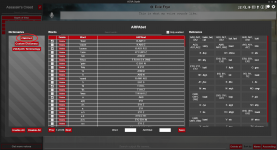
Gui Zhang * added
Ine-san * added
Nozomi Harasaki * added
Mark Kimberly * added
Joy added
Shenhua added
NON-Shenmue:
Metal Gear Solid:
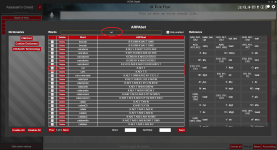
Colonel Campbell (Twin Snakes) added
Nastasha Romanenko (Twin Snakes) added
Naomi Hunter (MGS4) added
Raiden (MGRR) added
Sunny (MGRR) added
Dragon Ball:
Android 18 (Casual) added
Vegeta added
Resident Evil:
Jill Valentine (Resident Evil 3 1999) added
Leon S. Kennedy (RE4) added
Ingrid Hannigan (RE4) added
Mortal Kombat:
Cassie Cage added
Mileena added
Other:
ADA (Zone of the Enders) added
Madara Uchiha (Naruto) added
Balalaika (Black Lagoon) added
Alyx Vance (HL: A) added
Maleficent (Disney Infinity) added
 Contains some references to Discord users. In the event that throws you off.
Contains some references to Discord users. In the event that throws you off.
I plan on training some voice models from the Shenmue series for xVASynth. It may be useful for anyone who wants to add custom voiced lines to the game(provided you can re-import the audio that is), or you could simply use it just to play around with.
A basic rundown on how to use the software.
Installation: Copy and extract the voice model zip into the root directory of xVASynth.
Update: Ren was a failure. Will have to retrain at some point.
Bug: models marked with a ' * ' have quality degradation issues when generating sentences in succession(might just be my system). As a temporary fix: generate audio for desired model, type in new sentence, change to another model and generate, then switch back.
Gui Zhang * added
Ine-san * added
Nozomi Harasaki * added
Mark Kimberly * added
Joy added
Shenhua added
NON-Shenmue:
Metal Gear Solid:
Colonel Campbell (Twin Snakes) added
Nastasha Romanenko (Twin Snakes) added
Naomi Hunter (MGS4) added
Raiden (MGRR) added
Sunny (MGRR) added
Dragon Ball:
Android 18 (Casual) added
Vegeta added
Resident Evil:
Jill Valentine (Resident Evil 3 1999) added
Leon S. Kennedy (RE4) added
Ingrid Hannigan (RE4) added
Mortal Kombat:
Cassie Cage added
Mileena added
Other:
ADA (Zone of the Enders) added
Madara Uchiha (Naruto) added
Balalaika (Black Lagoon) added
Alyx Vance (HL: A) added
Maleficent (Disney Infinity) added
METAL GEAR SOLID:
Solid Snake (MGS1)
Colonel Campbell (MGS1)
Colonel Campbell (Twin Snakes)
Meryl Silverburgh (MGS1)
Mei Ling (MGS1)
Nastasha Romanenko (MGS1)
Nastasha Romanenko (Twin Snakes)
Naomi Hunter (MGS1)
Naomi Hunter (Twin Snakes)
Naomi Hunter (MGS4)
The Boss (Snake Eater)
Drebin 893 (MGS4)
Raiden (MGRR)
Sunny (MGRR)
DRAGON BALL:
Caulifla
Android 18
Android 18 (Casual)
Hercule
Chi-Chi
Chi-Chi (Calm)
Vegeta
LEGACY OF KAIN:
Kain
Umah
TEKKEN:
Nina Williams
Craig Marduk
RESIDENT EVIL:
Claire Redfield (Resident Evil 2 1998)
Jill Valentine (Resident Evil 3 1999)
Leon S. Kennedy (RE4)
Ingrid Hannigan (RE4)
MORTAL KOMBAT:
Cassie Cage
Mileena
OTHER:
Yuna (Final Fantasy)
Lara Croft (Tomb Raider II & III)
D-Tritus (Scrapland)
Elise Schwarzer (The Legend of Heroes)
ADA (Zone of the Enders)
Madara Uchiha (Naruto)
Balalaika (Black Lagoon)
Alyx Vance (HL: A)
Maleficent (Disney Infinity)
Solid Snake (MGS1)
Colonel Campbell (MGS1)
Colonel Campbell (Twin Snakes)
Meryl Silverburgh (MGS1)
Mei Ling (MGS1)
Nastasha Romanenko (MGS1)
Nastasha Romanenko (Twin Snakes)
Naomi Hunter (MGS1)
Naomi Hunter (Twin Snakes)
Naomi Hunter (MGS4)
The Boss (Snake Eater)
Drebin 893 (MGS4)
Raiden (MGRR)
Sunny (MGRR)
DRAGON BALL:
Caulifla
Android 18
Android 18 (Casual)
Hercule
Chi-Chi
Chi-Chi (Calm)
Vegeta
LEGACY OF KAIN:
Kain
Umah
TEKKEN:
Nina Williams
Craig Marduk
RESIDENT EVIL:
Claire Redfield (Resident Evil 2 1998)
Jill Valentine (Resident Evil 3 1999)
Leon S. Kennedy (RE4)
Ingrid Hannigan (RE4)
MORTAL KOMBAT:
Cassie Cage
Mileena
OTHER:
Yuna (Final Fantasy)
Lara Croft (Tomb Raider II & III)
D-Tritus (Scrapland)
Elise Schwarzer (The Legend of Heroes)
ADA (Zone of the Enders)
Madara Uchiha (Naruto)
Balalaika (Black Lagoon)
Alyx Vance (HL: A)
Maleficent (Disney Infinity)
Attachments
Last edited: